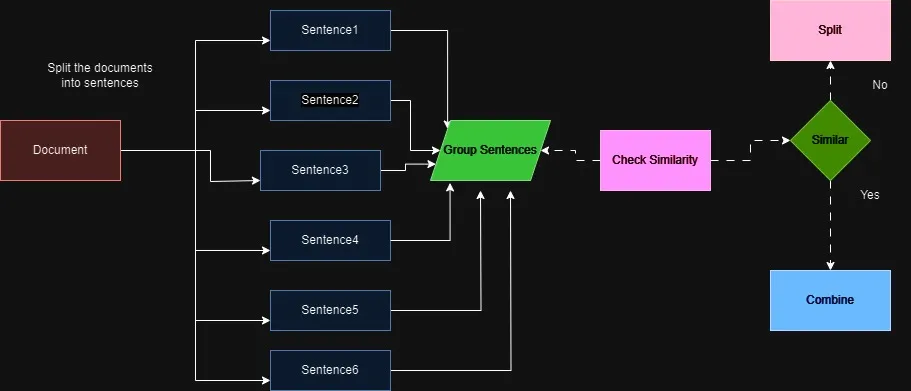
Chunking Strategy
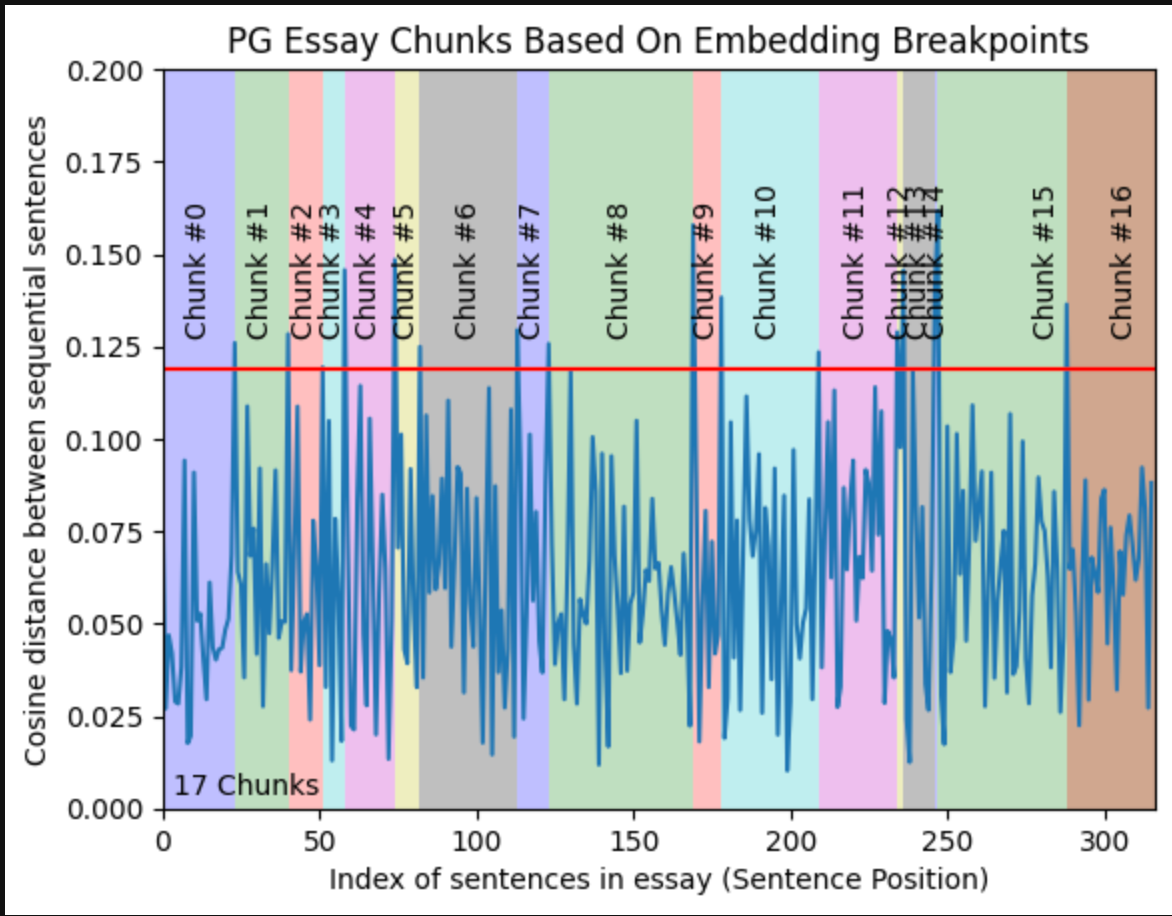
The main idea behind semantic chunking is to split a given text based on how similar the chunks are in meaning. This similarity is calculated by chunking the given text into sentences, then turning all these text-based chunks into vector embeddings and calculating the cosine similarity between these chunks. After that, we initialize a threshold, for example, 0.8, and whenever the cosine similarity between 2 consecutive segments is more than that, a split is done there.
Why Finetune?
With just a handful of examples, a fine-tuned open source embedding model can provide greater accuracy at a lower price than proprietary models like OpenAI’s text-embedding-3 suite of models
How to Finetune?

Dataset
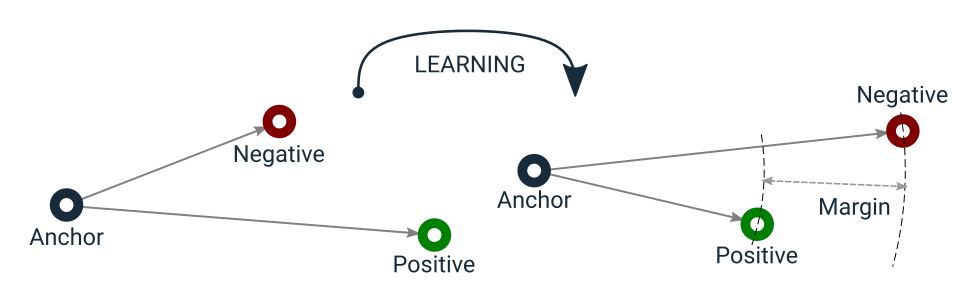
Triplets: Text triplets consisting of (query, positive context, negative context). In our case, the dataset is generated through an LLM (Claude 3.5) by asking it to generate a triplet of query and the corresponding positive context from which the query can be answered. We use a technique called In-batch Sampling to generate negative contexts.
As an Example
Positive Context: So we have kind of the way that we're going to market with what you just described with like Pac to you and sky, something we call shelf intelligent media. It's, we have a team, product team that's specifically leading that. So depending on how the conversation goes, we may introduce you to that team. So this, I can go into more of that strategy after we just do quick intros. So it's, we have, you know, we know who the core platforms are and then obviously that's part of like, what agencies are really used to using. And so as long, you know, if our clients are using a technology, our general, it's usually enterprise is our focus.
Loss Function
The Loss function chosen was MultipleNegativesRankingLoss
For each a_i, it uses all other p_j as negative samples, i.e., for a_i, we have 1 positive example (p_i) and n-1 negative examples (p_j). It then minimizes the negative log-likelihood for softmax normalized scores.
Model Selection
Model Comparison Table
| Rank | Model | Model Size (Million Parameters) | Memory Usage (GB, fp32) | Average |
|---|---|---|---|---|
| 1 | stella_en_1.5B_v5 | 1543 | 5.75 | 61.01 |
| 8 | stella_en_400M_v5 | 435 | 1.62 | 58.97 |
| 13 | gte-large-en-v1.5 | 434 | 1.62 | 57.91 |
| 33 | bge-large-en-v1.5 | 335 | 1.25 | 54.29 |
| 25 | text-embedding-3-large - openAI | 55.44 |
Evaluators
Evaluators chosen were Hit-Rate@k and Recall@k. Rank aware metrics did not make much sense since we did not have ranks of retrieved for gold-labelled dataset as well
Results comparing the performance of Finetuned Embeddings and OpenAI Embeddings for the same dataset for different chunk sizes
This contains the results of experiments that we performed to test the deal extraction pipeline!
Dataset: Synthetically generated QnA data over multiple transcripts for 60 deals using Claude 3.5
Results of Current Prod System V/S FineTuned Model (w/Chunking) on Human Labelled Dataset (Batch 1)
The results will be updated as more batches of human labelled datasets come